在大数据平台或应用中,为了降低数据传输消耗,通常我们会使用某种紧凑型的数据格式,比如Avro
Avro的序列化/反序列化JAVA API主要有两种,DataFileWriter/DataFileReader和GenericDatumWriter/GenericDatumReader
GenericDatumWriter/GenericDatumReader
1 | public static GenericRecord genericDatumSerde(Schema schema, GenericRecord record) throws IOException { |
这是比较常用的API,序列化之后的byte array不包含schema信息,因此反序列化构建GenericDatumReader时需要提供schema
DataFileWriter/DataFileReader
1 | public static GenericRecord dataFileSerde(Schema schema, GenericRecord record) throws IOException { |
与GenericDatumSerde相比,这种方式序列化之后的数据带有schema信息,因此byte array明显要大很多,但好处是反序列化构建GenericDatumReader时不需要提供schema
元数据管理
一般来说在大数据平台或应用中,从节省存储空间和带宽的角度来说,GenericDatumSerde会比较常用(以下如果没有特殊说明,都只讨论GenericDatumSerde)。但由于本身不带schema信息,上下游系统就必须额外的维护相同的或兼容的schema。在复杂的数据平台中,假如每个应用都在本地维护schema,那么数据格式的依赖关系是一种网状结构,当schema需要变更时,会带来相当大的麻烦
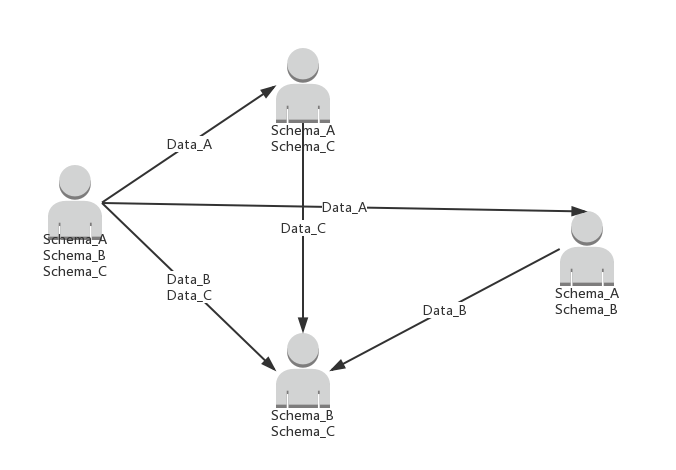
这时我们需要引入一个第三方的元数据管理系统,比如SchemaRegistry,这样数据格式的依赖关系就变成了星型结构
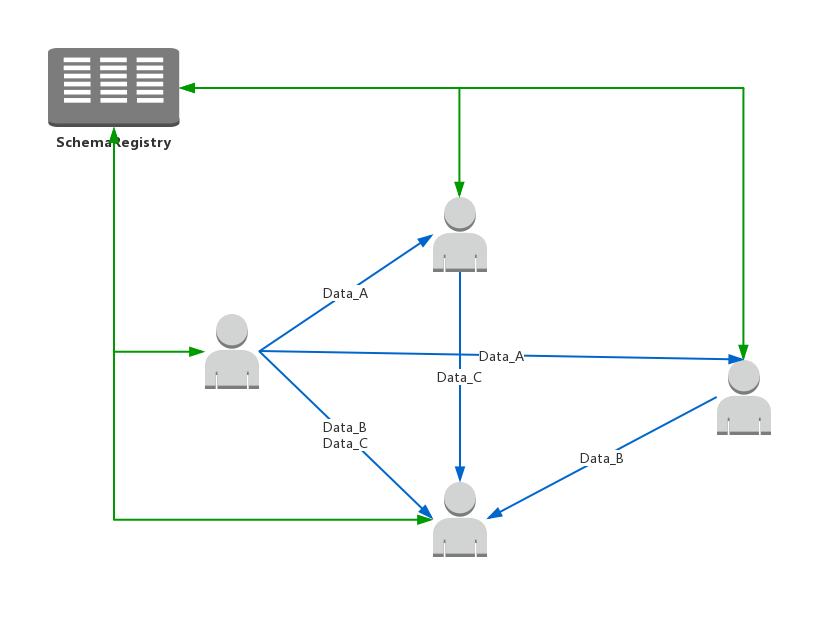
以Kafka作为数据交互中间件为例,Producer首先到SchemaRegistry中获取当前topic的schema,对数据进行avro序列化之后发送到Kafka,Consumer读取二进制数据,从SchemaRegistry中获取schema,对数据进行反序列化
Schema兼容性
考虑这样一种场景,Producer使用v1版本的schema对数据进行序列化,然后schema在SchemaRegistry中被更新到v2,比如添加了一个字段A,然后Consumer使用v2版本的schema对数据进行反序列化,就会抛出java.io.EOFException,原因是当尝试用新的schema解析字段A时,byte array中已经没有更多的数据可供读取
解决这个问题有两种办法:
- 用旧版本的schema反序列化
这里涉及到schema版本号传递的问题,最简单的办法当然是使用DataFileSerde,数据自带schema,不会出现版本不一致的问题,但刚才提到过,由于占用空间太大一般不用这种方式。换一种思路,数据本身只携带schema的id或version,本身占用空间很小,并且可以根据id找到序列化的旧版本schema
携带id有两种做法,一种是在byte array中分配一段固定长度的空间用于保存id,例如SchemaRegistry自带的KafkaAvroSerializer.java就是在byte array中预留前五个字节,其中第一个字节是魔法字节,4个字节用于保存id。读取时先根据第一个字节判断该条记录是否带有schema信息,如果是魔法字节,则从2-5个字节取出id,到SchemaRegistry中获取序列化所用的schema,然后对byte array中剩下的数据进行反序列化,这种做法实际上是对数据有侵入,导致byte array可读性降低(虽然本来可读性就不高)。另一种做法是使用额外的meta空间保存id,例如Kafka message的header,Flume event的header等等
- 忽略新增字段
1 | package org.apache.avro.generic; |
继承GenericDatumReader.java,重写readRecord方法,如果没有更多的数据可供读取,则直接忽略该字段。这样对于字段的增删都能够很好的兼容,但对于字段更新就没办法了(包括更新字段名和字段类型)
