前提
- 通过id去重,而不是整条数据
- id由SnowFlake算法生成,参考之前的文章SnowFlake算法在数据链路中的应用
需求
在实时平台的各个环节中,由于网络或其他问题,有时会出现数据重复的情况,本质上是由于at least once保障机制造成的。例如
- flume agent之间的数据传输,如果网络不稳定,有可能出现src_agent发送数据超时而导致重发,但实际上dest_agent已经收到,造成了数据重复
- kafka producer发送数据且设置acks=all,在replication完成之间就由于超时而返回失败,如果retries不为0,那么重发之后数据也会有重复
通常我们会在业务端通过幂等性来保证数据的唯一性,比如Mysql的primary key,或者是HBase的rowkey。但在流式计算或某些存储介质中,没有办法天然的实现数据去重,这时就需要在数据计算/存储之前将重复的数据移除或忽略
思路
我司的实时数据都是通过Flume采集,并且通过SnowFlake算法给每条数据分配一个全局唯一长整型的id,这个id会被带到整条数据链路中,所以考虑开发一个去重模块,对实时数据进行预处理。又由于id是数字类型,可以考虑用BitSet进行存储以提高查询效率和减小开销,但java.util.BitSet的最大长度是Integer.MAX_VALUE(2GB),再长的话内存开销就会非常巨大,所以需要对id进行分段存储
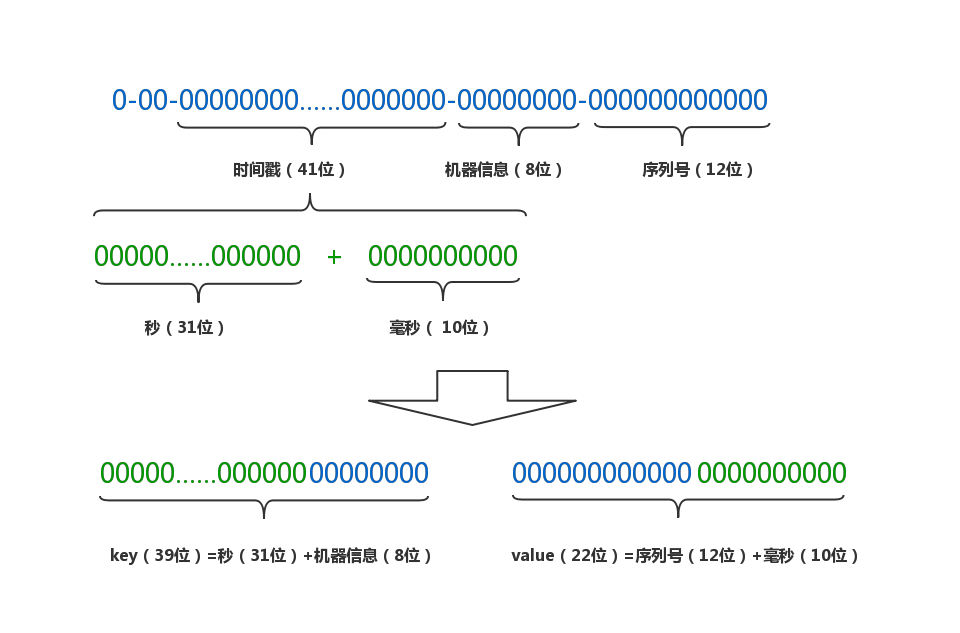
- 原始的id是由41位时间戳,8位机器信息和12位序列号组合而成
- 将时间戳拆分成秒和毫秒两部分
- 重新将各部分组合成新的key-value pair,秒数和机器信息拼接为一个long型的key,序列号和毫秒数拼接成一个int型的value。假设对n分钟内的数据进行过滤,则key的最大个数为n*60*256,value最大个数为4096*1000
- 将相同key的数据放到同一个BitSet中,并缓存到LoadingCache中
代码
注意:DuplicationEliminator中的常量必须与SnowFlake算法中一致,否则会解析错位
1 | import java.util.BitSet; |
测试
测试写入一亿个id,耗时48.4s,QPS=206.6万,内存占用68MB,性能和开销都还可以
1 | public static void main(String[] args) throws ExecutionException, InterruptedException { |
